Real World Lessons on How to Minimize Run Time for ANSYS HPC
Recently I had a VP of Engineering start a phone conversation with me that went something like this. “Well Dave, you see this is how it is. We just spent a truckload of money on a 256 core cluster and our solve times are slower now than with our previous 128 core cluster. What the *&(( is going on here?!”
I imagine many of us have heard similar stories or even received the same questions from our co-workers, CEO’s & Directors. I immediately had my concerns and I truly thought carefully as to what I should say next. I recalled a conversation I had with one of my college professors. He had told me that when I find myself stepping into gray areas that a good start to the conversation is to say. “Well it depends…”
Guess what, that is exactly what I said. I said “Well it depends…” followed by going into explaining to him two fundamental pillars of computer science that have plagued most of us since computers were created: I said “Well you may be, CPU bound (compute bound) or I/O bound. He told me that they had paid a premium for the best CPU’s on the market and some other details about the HPC cluster. Garnering some of other details about the cluster my hunch was that his HPC cluster may actually be I/O bound.
I/O Bound
Basically this means that your cluster’s $2,000 worth of CPU’s are basically stalled out and sitting idle. The CPU’s are waiting for new data to process and move on. I also briefly explained that his HPC cluster may be compute bound. I quickly reassured him that the likelihood of his HPC cluster being compute bound was about 10% possible and very unlikely. I knew the specifications on the CPU’s in this HPC cluster and the likelihood that they were the issue of his ANSYS slow run times was low on my radar. These literally were the latest and greatest CPU’s ever to hit this planet (at that moment in time). So, let me step back a minute, to refresh our memories on what it means when a system is compute bound.
Compute Bound
Being compute bound means that the HPC cluster’s CPU’s were sitting at 99 or 100% for long periods of time. When this happens very bad things begin to happen to your HPC cluster. CPU requests to peripherals are delayed or infinitely lost to the ether. The HPC cluster may become unresponsive and even lock up.
All I could hear was silence on the other end. “Dave, I get it, I understand, please find the problem and fix our HPC cluster for us. ” I happily agreed to help out! I concluded our phone conversation asking that he send me the specific details, down to the nuts and bolts of the hardware! I also requested operating system and software that was installed and used on the 256 core HPC cluster.
What NOT to do when configuring an ANSYS Distributed HPC cluster.
Seeking that perfect balance!
After a quick NDA signing, a few dollars exchange and a sprinkle of some other legal things that lawyers get excited about. I set out to discover the cause. After reviewing the information provided to me I almost immediately saw three concerns:
To interconnect what?
Let Merriam-Webster describe it:
transitive verb
: to connect with one another
intransitive verb
: to be or become mutually connected— in·ter·con·nec·tion noun
— in·ter·con·nec·tiv·i·ty noun1. The systems are interconnected with a series of wires.
2. The lessons are designed to show students how the two subjects interconnect
3. A series of interconnecting storiesFirst Known Use of INTERCONNECT: 1865
Concern numeral Uno!!! Interconnect me
Though the company’s 256 core HPC cluster had a second dedicated GigE interconnect. Distributed ANSYS is highly bandwidth and latency bound often requiring more bandwidth than a dedicated NIC (Network Interface Card) may provide. Yes, the dedicated second GigE card interconnect was much better than trying to use a single NIC for all of the network traffic which would also include the CPU interconnect. I did have a few of the MAPDL output files from the customer that I could take a peek at. After reviewing the customer output files it became fairly clear that interconnect communication speeds between the 16 core x 16 server in the cluster was not adequate. The master Message Parsing Interface (MPI) process that Distributed ANSYS uses requires a high amount of bandwidth and low latency for proper distributed scaling to the other processes. Theoretically the data bandwidth between cores solving local to the machine will be higher than the bandwidth traveling across the various interconnect methods (see below). ANSYS, Inc. recommends Infiniband for CPU interconnect traffic. Here are a couple of reasons why they recommend this. See how the theoretical data limits increase going from Gigabit Ethernet up to FDR Infiniband.
Theoretical lane bandwidth limits for:
- Gigabit Ethernet (GigE): ~128MB/s
- Signal Data Rate (SDR): ~ 328 MB/s
- Double Data Rate (DDR): ~640 MB/s
- Quad Data Rate (QDR): ~1,280 MB/s
- Fourteen Data Rate (FRD): ~1,800 MB/s
GEEK CRED: A few years ago companies such as MELLANOX started aggregating the Infiniband channels. The typical aggregate modifiers are 4X or even a 12X increase. So for example the 4X QDR Infiniband switch and cards I use at PADT and recommended to this customer, would have a (4X 10Gbit/s) or 5,120 MB/s of throughput! Here is a quick video that I made of a MELLANOX IS5023 18-port 4X QDR full bi-directional switch in action:
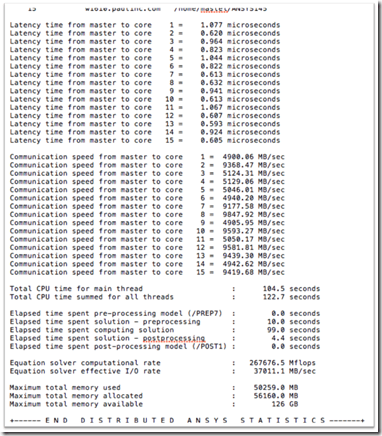
This is how you do it with a CUBE HVPC! MAPDL output file from our CUBE HVPC w16i-GPU workstation. This is running the ANSYS industry benchmark V14sp-5. I wanted to show the communication speeds between the master MPI process and the other solver processes to see just how fast the solvers can communicate. With a peak communication speed of 9593 MB/s this CUBE HVPC workstation rocks!
| Chassis Profile | 4u standard depth or rackmountable |
| CPU | 1 x One Dual Socket |
| Chipset | INTEL 602 Chipset |
| Processors | 2 x INTEL e5-2690 @ 2.9GHz |
| Cores | 2 x 8 |
| Memory | 128GB DDR3-1600 ECC Reg RAM |
| OS Drives | 2 x 2.5″ SATA III 256GB SSD Drives RAID 0 |
| DATA/HOME Hard Disk Drives | 4 x 3.5″ SAS2 600GB 15kRPM drives RAID 0 |
| SAS RAID (Onboard, Optional) | RAID 0 (OS RAID) |
| SAS RAID (RAID card, Optional) | LSI 2208 (DATA VOL RAID) |
| Networking (Onboard) | Dual GigE (Intel i350) |
| Video (Onboard) | NVIDIA QUADRO K5000 |
| GPU (Optional) | NVIDIA TESLA K2000 |
| Operating System | Windows 7 Professional 64-bit |
| Optional Installed Software | ANSYS 14.5 Release |
 Stats for CUBE HVPC Model Number : w16i-KGPU
Stats for CUBE HVPC Model Number : w16i-KGPU
Learn more about this and other CUBE HVPC systems here.
Concern #2: Using RAID 5 Array for Solving Disk Volume
The hard drives that are used for I/O during a solve, the solving volume, were configured in a RAID 5 hard disk array. Some sample data below showing the minimum write speed of a similar RAID 5 array. These are speeds that are better off seen in your long-term storage volume not on your solving/working directory.
| LSI 2008 | HITACHI ULTASTAR 15K600 |
| Qty / Type / Size / RAID | Qty 8 x 3.5″ SAS2 15k 600GB RAID 5 |
| TEST # | p1 |
| min Read | 204 MB/s |
| max Read | 395 MB/s |
| Avg Read | N/A |
| min Write | 106 MB/s |
| max Write | 243.5 MB/s |
| Avg Write | N/A |
| Access Time | N/A |
Concern #3: Using RAID 1 for Operating System
The hard drive array for the OS was configured in a RAID 1 configuration. For a number cruncher server having RAID 1 is not necessary. If you absolutely have to have RAID 1. Please spend the extra money and go to a RAID 10 configuration.
I really don’t want to get into the seemingly infinite details of hard drives speeds, latency. Or even begin to explain to you if I should be using an onboard RAID Controller, dedicated RAID controller or a software RAID configuration completed within the OS. There is so much information available on the web that a person gets overloaded. When it comes to Distributed ANSYS, think fast hard drives and fast RAID controllers. Start researching your hard drives and RAID controllers using the list provided below. Again, only as a suggestion! I have listed the drives in order based on a very scientific and nerdy method. If I saw a pile of hard drives, what hard drive would I reach for first?
- I prefer using SEAGATE SAVVIO or HITACHI enterprise class drives. (Serial Attached SCSI) SAS2 6Gbit/s 3.5”15,000 RPM spindle drives (best bang for your dollar of space, more read & write heads over a 2.5” spindle hard drive).
- I prefer using Micron or INTEL SSD enterprise class SSD. SATA III Solid State Drive 6 Gbit/s (SSD sizes have increased however you will need more of these for an effective solving array and they still are not cheap).
- I prefer using the SEAGATE SAVVIO 2.5” enterprise class spindle drives. SAS2 6Gbit/s 2.5” 15,000 RPM spindle drives (if you need a small form factor, fast and additional storage. But the 2.5” drives do not have as many read & write heads as a 3.5” drive. In a situation where I need to slam 4 or 8 drives into a tight location.
Right now, SEAGATE SAVVIO 2.5” are the way to go! Here is a link to a data sheet.
Another similar option is the HITACHI ULTRASTAR 15k600. It’s spec sheet is here. - SATA II 3Gbit/s 3.5” 7,200 RPM spindle drives are also a good option. I prefer Western Digital RE4 1TB or 2TB drives. There spec sheet is here.
LSI 2108 RAID Controller and Hard Drive data/details:

How a CUBE HVPC System from PADT, Inc. balanced out this configuration and how much would it cost?
I quoted out the below items, installed and out the door (including my travel expenses, etc.) at: $30,601
The company ended up going with their own preferred hardware vendor. Understandable, one good thing is that we are now on the preferred purchasing supplier list. They were greatly appreciative of my consulting time and indicated that they will request a “must have” quote for a CUBE HVPC system the next refresh in a year. They want to go over 1,000 cores the next refresh.
I recommended that they install the following into the HPC cluster based: (note they already had blazing fast hard drives)
- 16 – Supermicro AOC-S2208L-H8iR LSI 2208 RAID controller cards.
- 32 – Supermicro CBL-0294L-01 cabling to connect the LSI RAID cards to the SAS2 hard drives.
- 1 – MELLANOX IS5023 18-port 4X QDR Infiniband switch
- 16 – Supermicro AOC-UIBQ-M2 Dual port 4X QDR Infiniband card
- 16 – Supermicro QSFP Infiniband cables in a couple different lengths
A special thanks and shout out to Sheldon Imaoka of ANSYS, Inc. for inspiring me to write this blog article!